-
- 文本转语音ttsai模型ai大模型大模型Seed-TTSSeed-TTS 是一系列高质量文本到语音(TTS)模型,旨在生成高度逼真、自然流畅的语音。该模型基于深度学习和神经网络技术,通过大规模数据训练和复杂的算法设计,能够生成与人类语音几乎无法区分的语音。


Seed-TTS是由字节跳动开发的一种新型多功能的文本到语音(Text to Speech, TTS)生成模型,它基于自回归Transformer架构,只需要简短的语音片段,即可克隆生成高质量、几乎无法与人类语音区分的语音。Seed-TTS在语音上下文学习方面表现出色,特别是在说话者相似度和自然度方面,可以生成高度自然且富有表现力的语音。此外,Seed-TTS还支持情感、语调和说话风格等多属性的控制,并且能够通过编辑文本来编辑生成的语音,使其适用于多种应用场景,如有声读物、视频配音及多语言翻译等。

核心功能
- 高质量语音生成:
- Seed-TTS 能够生成高度自然、富有表现力的语音,音质、音调和情感表达接近真人水平。
- 支持多种语言的文本输入,生成相应语言的语音。
- 上下文学习与零样本学习:
- 模型具备强大的上下文学习能力,能够根据文本语境生成连贯、一致的语音。
- 支持零样本学习,即使没有特定说话者的训练数据,也能快速生成高质量语音。
- 情感与语音属性控制:
- 用户可以指定语音的情感色彩(如喜悦、悲伤、愤怒等),模型会相应调整音调、强度和节奏。
- 支持对语调、节奏和说话风格的控制,满足不同应用场景的需求。
- 语音编辑与转换:
- 支持对生成语音的内容编辑和速度调整,满足个性化需求。
- 提供语音分解功能,可将音色与其他属性分离,实现更灵活的控制。
- 自蒸馏与强化学习:
- 采用自蒸馏方法实现语音属性分解,提升模型的鲁棒性和可控性。
- 引入强化学习技术,进一步优化模型性能。
模型架构
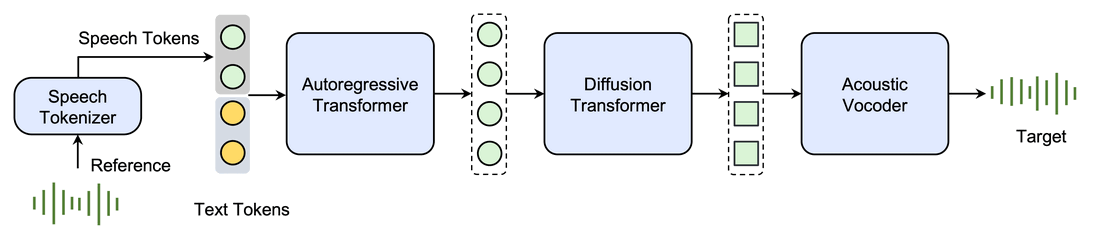
1、 语音分词器 (Speech Tokenizer)
Seed-TTS语音分词器将语音信号转换为离散的语音 token 序列。降低模型复杂度,提高训练效率。
2、 自回归模型(Autoregressive Transformer)
Seed-TTS自回归模型根据文本和语音 token 序列生成语音 token 序列。学习文本和语音之间的关系,生成自然流畅的语音。
3、扩散模型 (Diffusion Transformer)
Seed-TTS扩散模型根据语音 token 序列生成连续的语音特征表示。学习语音特征之间的关系,生成具有丰富细节的连续语音。
4、 语音合成器 (Acoustic Vocoder)
Seed-TTS语音合成器可以将语音特征表示转换为语音波形。生成高质量的语音波形。
如何使用
Seed-TTS目前处于论文和技术测试阶段,暂未对外开放使用,Seed-TTS官网提供了一个在线演示地址,感兴趣的同学可以前去查看,可以在线预览和播放试听各类风格的语音效果。
Seed-TTS官网在线演示地址:https://bytedancespeech.github.io/seedtts_tech_report/
- Seed-TTS arXiv论文地址:https://arxiv.org/html/2406.02430
- Seed-TTS 官方Github项目地址:https://github.com/BytedanceSpeech/seed-tts-eval
应用场景
- 虚拟助手:
- 提供自然流畅的语音交互,提升用户体验。
- 有声读物与音频内容:
- 将电子书籍、新闻稿件等文本内容转换为有声读物,增强用户听觉体验。
- 视频配音:
- 为动画、广告、游戏等视频内容生成多样化配音,赋予角色鲜明个性。
- 教育与辅助工具:
- 制作有声教材,辅助语言学习;为残障人士提供语音合成服务。
- 客户服务:
- 生成自动语音回复,处理常规咨询,提升服务效率。
数据统计
特别声明&浏览提醒
本网站提供的「Seed-TTS」相关内容均来源于网络搜集整理,不保证跳转外部链接的准确性和完整性。网站外部链接的内容在[2025-05-05]录入之前合规合法,后期网站的内容如出现违规或者损害了您的利益,可以直接联系网站管理员进行删除。如果涉及到金钱交易,请仔细甄别,避免上当受骗!
 SkyReels-V2和SkyReels-V1相比,
SkyReels-V2和SkyReels-V1相比, Claude 4有什么特点,为什么
Claude 4有什么特点,为什么 Devin与GitHub Copilot相比有哪
Devin与GitHub Copilot相比有哪 MCP是什么?为什么说谁把
MCP是什么?为什么说谁把AI工具
热门标签
声音克隆(11) 虚拟人像(1) ai机器人(5) ai创作(14) 文本转语音(25) 人工智能模型(3) ai对话工具(43) ai聊天(41) CogAgent(1) 智能体模型(8) 智能编码(5) 语音合成(8) ai视频精修(8) AI视频创作(50) ai编程(27) ai图片生成(96) 大模型(13) 开源AI(27) ai翻译工具(18) ai小说写作(2) ai浏览器(4) ai电商工具(19) 大语言模型(6) ChatGLM2(1) 多模态(18) ai语音生成(13) ai双语翻译(1) ai文生视频(31) ai写作(26) ai大模型(17)