


请按 Ctrl+D 收藏本页到浏览器收藏夹回家不迷路!
JoyGen 是由京东科技与香港大学联合开发的音频驱动的3D说话人脸视频生成框架。以下是关于 JoyGen 的详细介绍:
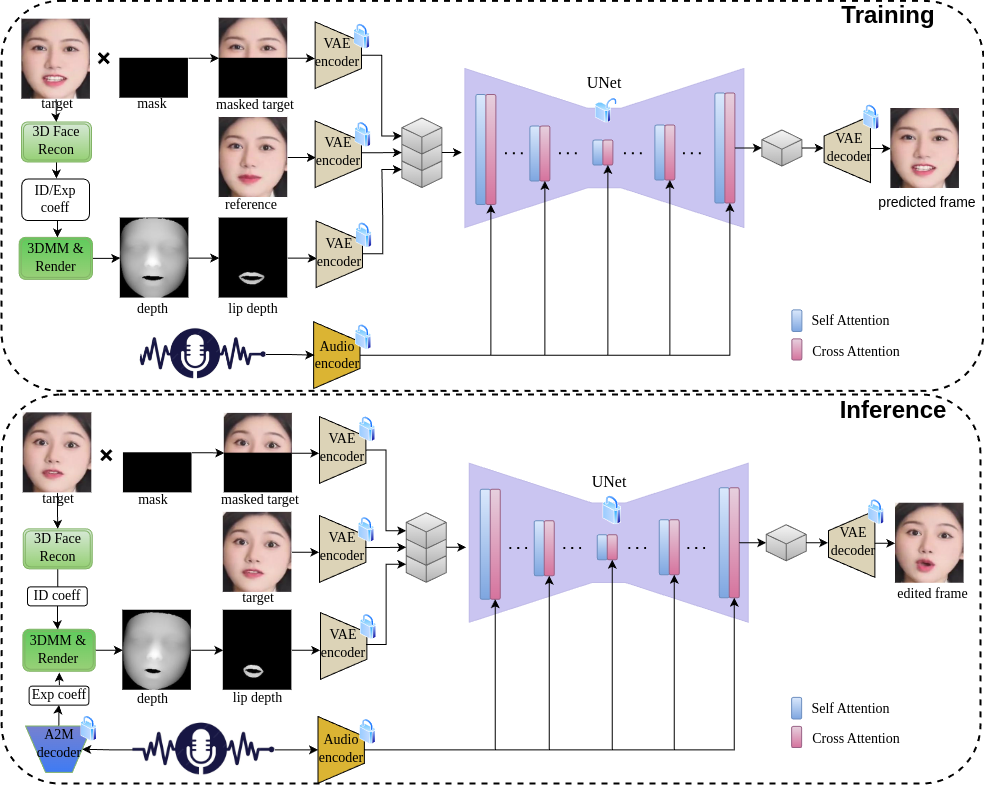
核心功能
- 精确的唇部与音频同步:通过音频驱动的唇部运动生成技术,结合音频特征和面部深度图,生成与输入音频精确同步的唇部运动,确保视频中人物的唇部动作与音频内容精准对应。
- 高质量视觉效果:利用单步 UNet 架构和潜在空间预测技术,生成逼真的视觉效果,包括自然的面部表情和清晰的唇部细节,避免模糊或失真。
- 视频编辑与优化:在现有视频的基础上进行唇部运动的编辑和优化,无需重新生成整个视频。
- 多语言支持:支持中文和英文等不同语言的视频生成,适应多种应用场景。
如何使用
JoyGen的训练代码、模型权重和示例视频均已开源,项目主页为 JoyGen GitHub
- 环境搭建:用户需创建一个特定的conda环境,并安装必要的依赖包,包括Nvdiffrast等特定库。
- 预训练模型下载:获取JoyGen的预训练模型,包括3D模型、音频到运动模型等,这些资源通常在项目GitHub页面上提供。
- 运行推理:通过执行特定的脚本和参数,用户可以将音频文件转换为带有逼真唇部同步的3D说话人脸视频。
技术原理
- 第一阶段:音频驱动的唇部运动生成
- 3D 重建模型:从输入的面部图像中提取身份系数,用于描述人物的面部特征。
- 音频到运动模型:将音频信号转换为表情系数,控制唇部的运动。
- 深度图生成:结合身份系数和表情系数生成面部的 3D 网格,基于可微渲染技术生成面部深度图,用于后续的视频合成。
- 第二阶段:视觉外观合成
- 单步 UNet 架构:用单步 UNet 网络将音频特征和深度图信息整合到视频帧的生成过程中。UNet 基于编码器将输入图像映射到低维潜在空间,结合音频特征和深度图信息进行唇部运动的生成。
- 跨注意力机制:音频特征基于跨注意力机制与图像特征交互,确保生成的唇部运动与音频信号高度一致。
- 解码与优化:生成的潜在表示基于解码器还原为图像空间,生成最终的视频帧。基于 L1 损失函数在潜在空间和像素空间进行优化,确保生成视频的高质量和同步性。
应用场景
- 网络虚拟主持人及在线直播活动:构建虚拟主播来执行新闻报道和电子商务直播等功能,并依据提供的声音信号即时产生高度真实的嘴部动作,从而增强用户的观看感受。
- 动漫创作:在动画电影行业之中,迅速创建与语音配对吻合的口型动作序列,旨在减轻绘图人员的工作负担,并提升整体生产效能。
- 远程学习:创建模拟教师的形象,并使该形象的口型与授课音频相匹配,从而使教育视频更加鲜活有趣,进而提高学生的学术参与度和兴趣。
- 制作视频素材:助力创作者迅速制作出高品质的人像发言视频,包括虚拟角色的小品或幽默片段等内容,从而多样化创作的表现手法。
- 多种语言的视频创作:该功能具备多种语言的支持能力,能够迅速地把一段视频中的原始语音转译成用户所需的语言,并确保新的声音文件与人物口型完美匹配,极大地促进了全球范围内的文化内容分享和交流。
数据统计
特别声明&浏览提醒
本网站提供的「JoyGen」相关内容均来源于网络搜集整理,不保证跳转外部链接的准确性和完整性。网站外部链接的内容在[2025-07-13]录入之前合规合法,后期网站的内容如出现违规或者损害了您的利益,可以直接联系网站管理员进行删除。如果涉及到金钱交易,请仔细甄别,避免上当受骗!
 AI六小龙旗下产品有哪些,
AI六小龙旗下产品有哪些, SkyReels-V2和SkyReels-V1相比,
SkyReels-V2和SkyReels-V1相比, Claude 4有什么特点,为什么
Claude 4有什么特点,为什么 Devin与GitHub Copilot相比有哪
Devin与GitHub Copilot相比有哪日榜周榜
AI工具
热门标签
声音克隆(12) ai机器人(5) ai文生视频(40) AI视频创作(59) 虚拟人像(1) 人工智能模型(3) ai创作(15) 文本转语音(27) ai聊天(41) 智能编码(6) ai电商工具(20) ai对话工具(47) 大语言模型(6) CogAgent(1) 智能体模型(10) ai对话(27) ai图片生成(105) 大模型(13) 开源AI(32) 语音合成(9) ai视频精修(8) ai编程(28) ai翻译工具(20) ai语音生成(14) ai双语翻译(1) ai小说写作(3) ai浏览器(4) ai写作(28) ChatGLM2(1) 多模态(18)